
Why free text?
Marcell
25 Sep 2024
Free text is essential
Trying to understand what people think of your product or service with only quantitative surveying is like going to a concert with earplugs - you kind of hear the beat, but you will miss the real music. The richer story of emotions and nuances is missed entirely and associations outside of the questionnaire are not surfaced either.
On the flip side, whenever open-ended feedback is invited and analyzed, one is faced with the daunting reality: consistently digesting hundreds of pages of text takes hours and hours, if not several days of tedious work. Thus survey based research often becomes a balancing act between the cost of processing free text, and the opportunity cost of not acquiring comprehensive knowledge of what people really think.
If you only want to survey a few times each year, then absorbing the cost of processing free text surveys can be a reasonable proposition. However, doing this on a regular basis incurs a very steep cost most organizations are not willing to pay. Therefore, they opt to pay the opportunity cost of giving up on the nuances of valuable insights that free text feedback provides, favoring more scalable but less informative methods like multiple-choice surveys or quantitative metrics. This however, will inevitably have several downstream effects, which eventually result in less than ideal iterations of developing products and services.
If you think this sounds pretty grim, we agree! That’s why we made CrowdPrisma: to help you reimagine how you use surveys from now on.
Analyzing vast amounts of free text
Let’s take a step back, and see how we can get insights from text. There are two basic barriers we need to jump through to gain insights: text complexity & volume. Free text can represent a tapestry of complex ideas, where layers of meaning intertwine and reflect the writer’s abstract thought process. It captures subtle nuances, emotions, and connections that reveal deeper insights. Put this together with the fact that the more open questions you ask, the more complex and diverse ideas may be brought up by respondents, and you can see why across all industries, survey designers tend to refrain from using open ended questions.
Word based topic search
There are tools, such as Qualtrics, which help you extract topics based on the usage of words, or a combination of words. If you are after the three most frequently used words, for example, and you are happy with having a rough idea of what is mentioned in the text, this approach may be useful.
The limitations of this approach, however, are obvious. Firstly, any response which does not contain the words or word combinations of your choice, but does belong to the topic, will be left out of your search results entirely. You would need to write a very long, and completely bespoke filter to capture all relevant comments. Secondly, if the filter set is not specific enough, non relevant comments will be mixed into the search results.
We can illustrate this with a simple example. We have analyzed the 1600 guitar reviews from Amazon Review Data Collection. (We have written an entire blog post where you can see step by step how CrowdPrisma is used to pull out insights with a few clicks, and you can follow along in this dashboard.) In the dashboard we can see that there are 831 responses that include content related to design and appearance of the guitars. (Count in top left corner for selected “F” theme)
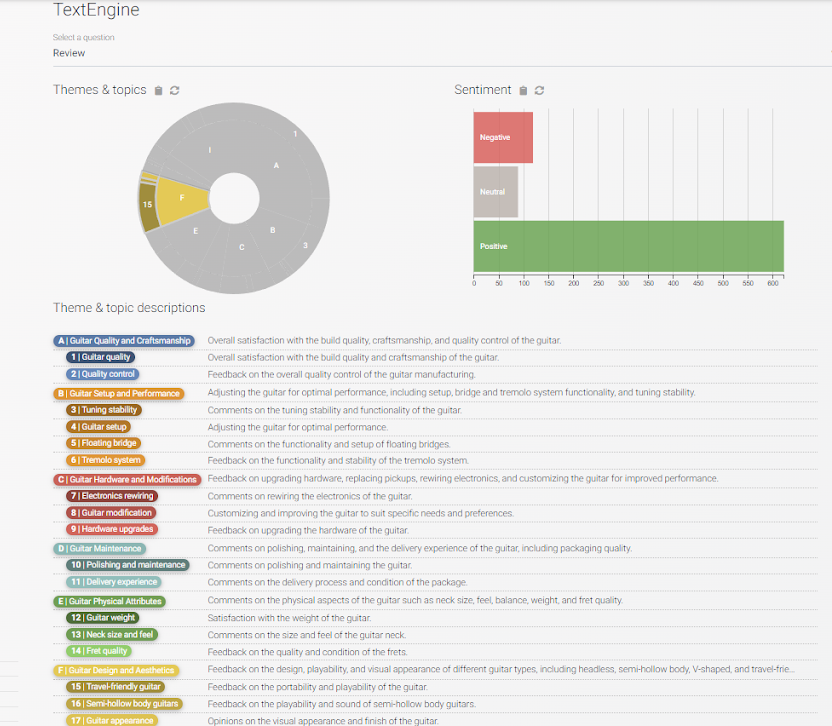
If we reset this filter and simply search for the words “body” or “look” for example, we get 569 comments.
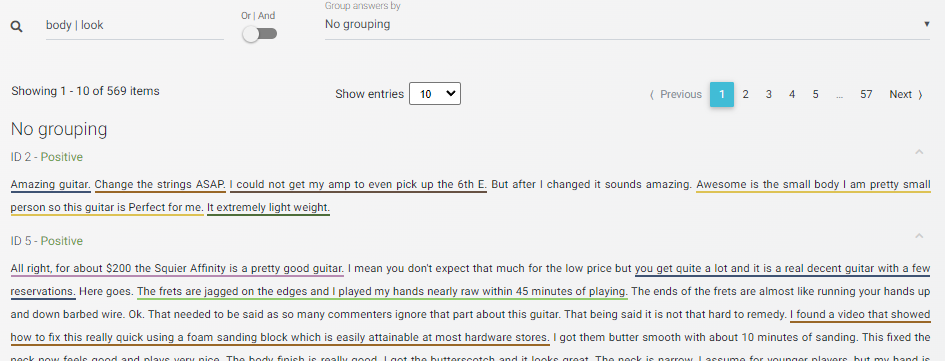
Applying both filters above, we get 459 comments. Simply looking for “body” or “look”, we miss half of the comments on design and appearance. This is the less surprising part. It also means that searching for two words only, we already introduce 20% false positives, i.e. comments that have no relevance to our real intended search. If we cast our net wider, this number only increases.
Through this simple example it’s easy to see that with words based approaches either way too much information is missed, or too much noise and irrelevant content is introduced when we try to distill the content in free text.
Analyzing free text using AI
Luckily, word based topic extraction methods are history. The latest AI models (Large Language Models or LLMs) have reached a level of complexity that allows them to effectively map and interpret free text in ways that were previously unimaginable, capturing the intricate layers of meaning, context, and intent behind each phrase. Even better, they can do this at scale, reading hundreds of pages spanning several languages, yet never get tired or lose their focus. However one question remains: can you trust the output of these models? Did the model find all the topics? Did it assign all responses to the relevant ones?
Unfortunately, due to the hallucinations and biases these models are prone to, we cannot just go ahead and chuck our data into a model. (Feel free to try it out if you don’t take our word for it.) Having topics or a brief summary extracted which is biased towards the beginning or the end of the text for example, is not really of use. In fact, it is tedious work to validate whether the model has assessed the text correctly and completely, and you may be almost back to square one.
Analyzing free text with CrowdPrisma
This is why we built CrowdPrisma, a platform for the in-depth understanding of free text survey data, so you can make the most of your respondents’ feedback. When working with AI, transparency and precision are key. In the CrowdPrisma engine there are hundreds of checks and validations run each and every single time you create an analysis, so that the topic generation is comprehensive and the assignment of comments to these topics is done with uncompromised precision.
Moreover, as seen in the screenshot above, the platform not only lists each comment that belongs to the topics you are interested in, but it highlights exactly which part of the response the topic appears in. Yes, various topics may appear in each comment, and anytime that’s the case, all of them are highlighted. The topics are organized into a theme & topic hierarchy and they can be easily combined with any other non-text variable to find groups of interest with just a few clicks.
Surveys re-imagined
With CrowdPrisma, we are enabling UX professionals to run qualitative and mixed method research studies much more frequently. Market researchers can now add open ended questions to quick surveys and offer more insight to clients. Free text responses of public policy research projects are finally treated as first class citizens, so that policy makers can actually have all the necessary nuances incorporated into their reports. Finally, HR departments can predict churn and employee dissatisfaction sooner and with more precision when they leverage free text feedback together with traditional score based approaches.
We strongly believe that surveying in all industries is at a watershed moment and old habits of avoiding open-ended questions will soon break to give way to a new era in research. We call this the “Era of why”. When you get to the “Why?” behind the “What?” and “How?”, you can design more beautiful products and services, create better experiences and policies and react to your customer’s or user’s needs quicker and more intelligently. That’s the power of why.